ai
Getting Started with AI for Digital Asset Management & Digital Collections
13 October 2023
Talk of artificial intelligence (AI), machine learning (ML), and large language models (LLMs) is everywhere these days. With the increasing availability and decreasing cost of high-performance AI technologies, you may be wondering how you could apply AI to your digital assets or digital collections to help enhance their discoverability and utility.
Maybe you work in a library and wonder whether AI could help catalog collections. Or you manage a large marketing DAM and wonder how AI could help tag your stock images for better discovery. Maybe you have started to dabble with AI tools, but aren’t sure how to evaluate their performance.
Or maybe you have no idea where to even begin.
In this post, we discuss what artificial intelligence can do for libraries, museums, archives, company DAMs, or any other organization with digital assets to manage, and how to assess and select tools that will meet your needs.

Examples of AI in Libraries and Digital Asset Management
Wherever you are in the process of learning about AI tools, you’re not alone. We’ve seen many organizations beginning to experiment with AI and machine learning to enrich their digital asset collections. We helped the Library of Congress explore ways of combining AI with crowdsourcing to extract structured data from the content of digitized historical documents. We also worked with Indiana University to develop an extensible platform for applying AI tools, like speech-to-text transcription, to audiovisual materials in order to improve discoverability.
What kinds of tasks can AI do with my digital assets?
Which AI methods work for digital assets or collections depends largely on the type of asset. Text-based, still image, audio, and video assets all have different techniques available to them. This section highlights the most popular machine learning-based methods for working with different types of digital material. This will help you determine which artificial intelligence tasks are relevant to your collections before diving deep into specific tools.
AI for processing text – Natural Language Processing
Most AI tools that work with text fall under the umbrella of Natural Language Processing (NLP). NLP encompasses many different tasks, including:
- Named-Entity Recognition (NER) – NER is the process of identifying significant categories of things (“entities”) named in text. Usually these categories include people, places, organizations, and dates, but might also include nationalities, monetary values, times, or other concepts. Libraries or digital asset management systems can use named-entity recognition to aid cataloging and search.
- Sentiment analysis – Sentiment analysis is the automatic determination of the emotional valence (“sentiment”) of text. For example, determining whether a product review is positive, negative, or neutral.
- Topic modeling – Topic modeling is a way of determining what general topic(s) the text is discussing. The primary topics are determined by clustering words related to the same subjects and observing their relative frequencies. Topic modeling can be used in DAM systems to determine tags for assets. It could also be used in library catalogs to determine subject headings.
- Machine translation – Machine translation is the automated translation of text from one language to another–think Google Translate!
- Language detection – Language detection is about determining what language or languages are present in a text.

AI for processing images and video – Computer Vision
Using AI for images and videos involves a subfield of artificial intelligence called Computer Vision. Many more tools are available for working with still images than with video. However, the methods used for images can often be adapted to work with video as well. AI tasks that are most useful for managing collections of digital image and video assets include:
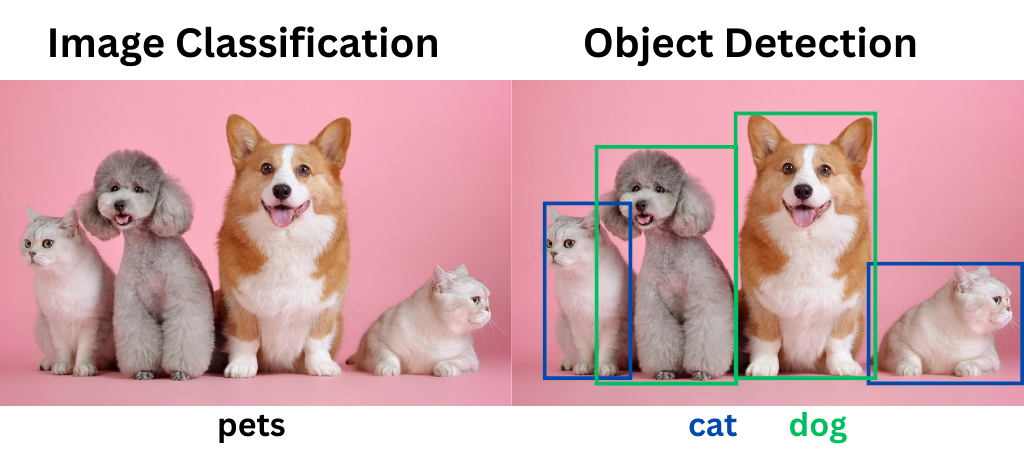
- Image classification – Image classification applies labels to images based on their contents. For example, image classification tools will label a picture of a dog with “dog.”
- Object detection – Object detection goes one step further than image classification. It both locates and labels particular objects in an image. For example, a model trained to detect dogs could locate a dog in a photo full of other animals. Object detection is also sometimes referred to as image recognition.
- Face detection/face recognition – Face detection models can tell whether a human face is present in an image or not. Face recognition goes a step further and identifies whether the face is someone it knows.
- Optical Character Recognition (OCR) – OCR is the process of extracting machine-readable text from an image. Imagine the difference between having a Word document and a picture of a printed document–in the latter, you can’t copy/paste or edit the text. OCR turns pictures of text into digital text.
AI for processing audio – Machine Listening
AI tools for working with audio are much fewer and farther between. The time-based nature of audio, as opposed to more static images and text, makes working with audio a bit more difficult. But there are still methods available!
- Speech-to-text (STT) – Speech-to-text, also called automatic speech recognition, transcribes speech into text. STT is used in applications like automatic caption generation and dictation. Transcripts created with speech-to-text can be sent through text-based processing workflows (like sentiment analysis) for further enrichment.
- Music/speech detection – Speech, music, silence, applause, and other kinds of content detection can tell you which sounds occur at which timestamps in an audio clip.
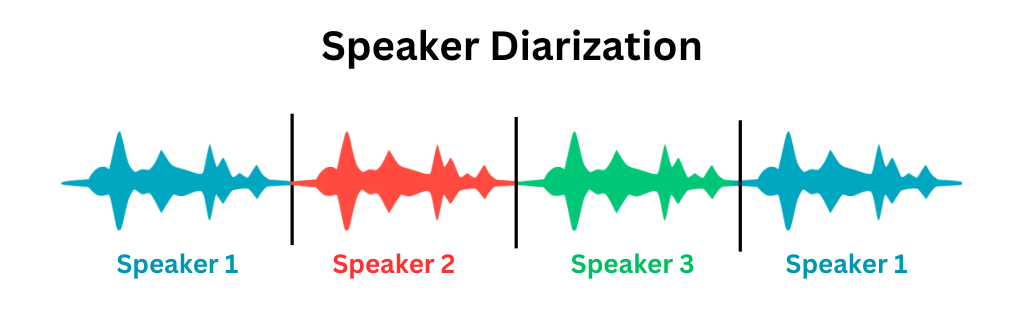
- Speaker identification / diarization – Speaker identification or diarization is the process of identifying the unique speakers in a piece of audio. For example, in a clip of an interview, speaker diarization tools would identify the interviewer and the interviewee as speakers. It would also tell you where in the audio each speaks.
What is AI training, and do I need to do it?
Training is the process of “teaching” an algorithm how to perform its task.
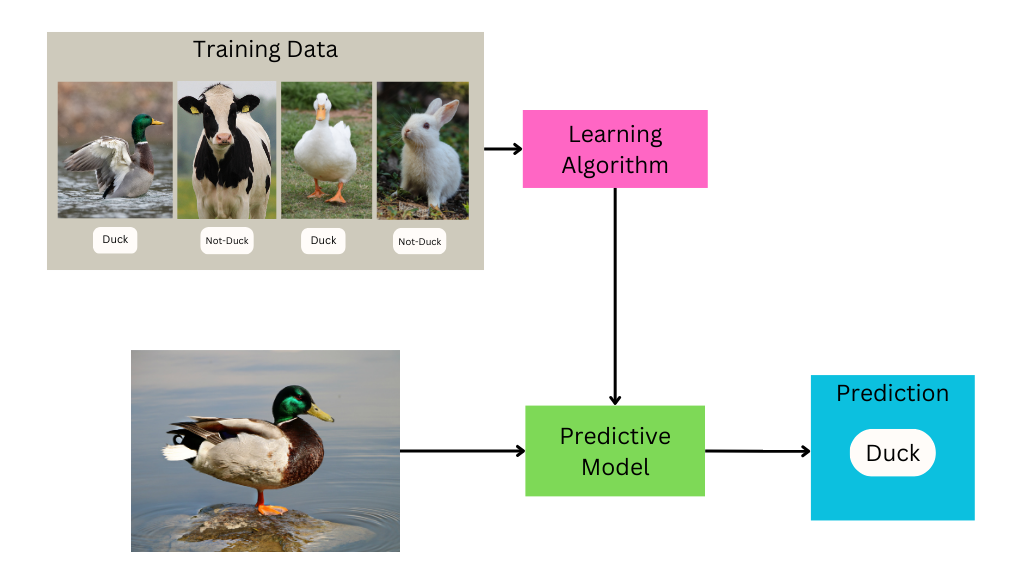
Creating a trained machine learning model involves developing a set of training data, putting that data through a learning algorithm, and tweaking parameters until it produces desirable results.
You can think of training data as the “answer key” to a test you want the computer to take.
For example, if the task you want to perform is image classification–dividing images into different categories based on their contents–the training data will consist of images labeled with their appropriate category. During the training process, the computer examines that training data to determine what features are likely to be found in which categories, and subsequently uses that information to make guesses about the appropriate label for images it’s never seen before.
In addition to the labeled data given to the algorithm for learning, some data has to be held back to evaluate the performance of the model. This is sometimes called “ground truth” testing, which we’ll discuss more below.
Developing training and testing data is often the most time-consuming and labor-intensive part of working with machine learning tools. Getting accurate results often requires thousands of sample inputs, which may (depending on the starting state of your data) need to be manually processed by humans before they can be used for training.
Training AI tools sounds costly, is it always necessary?
Custom training may not be required in all cases. Many tools come with “pre-trained” models you can use. Before investing loads of resources into custom training, determine whether these out-of-the-box options meet your quality standards.
Keep in mind that all machine learning models are trained on some particular set of data.
The data used for training will impact which types of data the model is well-suited for—for example, a speech-to-text model trained on American English may struggle to accurately transcribe British English, and will be completely useless at transcribing French.
Researching the data used to train out-of-the-box models, and determining its similarity to your data can help set your expectations for the tool’s performance.
Choose the right AI tool for your use case

Before you embark on any AI project, it’s important to articulate the problem you want to solve and consider the users that this AI solution will serve. Clearly defining your purpose will help you assess the risks involved with the AI, help you measure the success of the tools you use, and help you determine the best way to present or make use of the results for your users in your access system.
All AI tools are trained on a limited set of content for a specific use case, which may or may not match your own. Even “general purpose” AI tools may not produce results at the right level of specificity for your purpose. Be cautious of accuracy benchmarks provided by AI services, especially if there is little information on the testing process.
The best way to determine if an AI tool will be a good fit for your use case is to test it yourself on your own digital collections.
How to evaluate AI tools
Ground truth testing is a standard method for testing AI tools. In ground truth testing, you create examples of the ideal AI output (ground truth) for samples of your content and check them against the actual output of the AI to measure the tool’s accuracy.
For instance, comparing the results of an object recognition tool against the list of objects you expect the tool to recognize in a sample of images in your digital asset management system can show you the strengths of the AI in correctly identifying objects in your assets (true positives) and its weaknesses in either not detecting objects it should have (false negatives) or misidentifying objects (false positives).
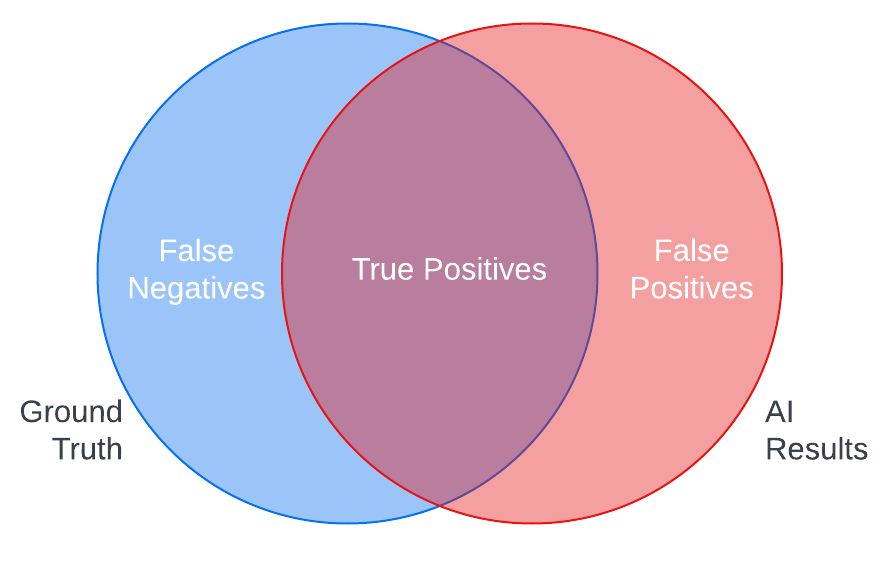
Common quantitative measures for ground truth testing include precision and recall, which can help you better calculate these risks of omission and misidentification. You can also examine these errors qualitatively to better understand the nature of the mistakes an AI tool might make with your content, so you can make informed decisions about what kind of quality control you may need to apply or if you want to use the tool at all.
Ground truth testing, however, can be costly to implement.
Creating ground truth samples is time-consuming, and the process of calculating comparison metrics requires specialized knowledge. It’s also important to keep in mind that ground truth can be subjective, depending on the type of tool—the results you’d expect to see may differ in granularity or terminology from the outputs the AI was trained to produce.
In the absence of ground truth, you can visually scan results for false positives and false negatives to get a sense of what kinds of errors an AI might make on your content and how they might impact your users.
Is it important that the AI finds all of the correct results? How dangerous are false positives to the user experience?
Seeing how AI results align with your answers to questions like these can help to quickly decide whether an AI tool is worth pursuing more seriously.
In addition to the quality of results, it is also important to consider other criteria when evaluating AI tools. What are the costs of the tool, both paid services and staff time needed to implement the tool and review or correct results? Will you need to train or fine-tune the AI to meet the needs of your use case? How will the AI integrate with your existing technical infrastructure?
To learn more about how you can evaluate AI tools for your digital assets with users in mind, check out AVP’s Human-Centered Evaluation Framework webinar, which includes a quick reference guide to these and many other questions to ask vendors or your implementation team.
When not to use artificial intelligence

With all of the potential for error, how can you decide if AI is really worth it? Articulating your goals and expectations for AI at the start of your explorations can help you assess the value of the AI tools you test.
Do you want AI to replace the work of humans or to enhance it by adding value that humans cannot or do not have the time to do? What is your threshold for error? Will a hybrid human and AI process be more efficient or help relieve the tedium for human workers? What are the costs of integrating AI into your existing workflows and are they outweighed by the benefits the AI will bring?
If your ground truth tests show that commercial AI tools are not quite accurate enough to be worth the trouble, consider testing again with the same data in 6 months or a year to see if the tools have improved. It’s also important to consider that tools may change in a way that erodes accuracy for your use case. For that reason, it’s a good idea to regularly test commercial AI tools against your baseline ground truth test scores to ensure that AI outputs continue to meet your standards.
Now what?
The topics we’ve covered in this post are only the beginning! Now that you’ve upped your AI literacy and have a basic handle on how AI might be useful for enhancing your digital assets or collections, start putting these ideas into action.
Learn how AVP can help with your AI selection or evaluation project
Where Do Humans Need To Be In The AI Loop? AVP Case Study
30 October 2021
In 2020 the Library of Congress Labs began the Humans in the Loop experiment to explore ways to responsibly combine crowdsourcing experiences and machine learning workflows. Through a public selection process, AVP was chosen as a project partner to collaboratively develop a framework for ethically, engagingly, and usefully incorporating human feedback via crowdsourcing into training data for machine learning processes. Machine learning’s reliance on pattern recognition and training decisions made by human annotators makes it really good at predicting past classifications. But complexities emerge especially when it comes to the potential to replicate and even proliferate bias and harmful effects. So where do humans need to be in the AI loop?
The project outcomes will provide structure and context for everyone in the machine-learning and libraries communities to better evaluate potential issues that arise through automated, AI-powered metadata enrichment processes. The project is also creating training data constructed with ethical guidelines that can be used by any organization using machine learning to enrich collections description and access. The Humans in the Loop experiment builds directly on LC Labs’ sustained exploration of machine learning in cultural heritage for tasks such as pre-processing, segmentation, classification, clustering, transcription, and extraction.
The team chosen historical Yellow Pages telephone directories that have been digitized for three interactive workflows experiments. Each workflow asked users to draw boxes around ads and text and transcribe highlighted text. The goal was to “teach” the computer how to parse out information from a single digitized page and understand different content types like ads or a directory listing.
Hear some of the Humans in the Loop team discuss how they see the project within an ethical, engaging, and useful context in the video embedded below or stream it here.
VIDEO: Project Discussion: Where Do Humans Need To Be In The AI Loop?
- Dr Meghan Ferriter, Senior Innovation Specialist with the National Digital Initiatives at the Library of Congress
- Natalie Burclaff, Business Reference Specialist, Library of Congress
- Shawn Averkamp, Senior Consultant, AVP
- Kerri Willette, Senior Consultant, AVP